|
Biwei Xie (解壁伟)
office at 1011F,
NO. 6, Kexueyuan South Road, Zhongguancun,
Haidian district, Beijing, P.R.China 100190
Email: xiebiwei(at)ict(dot)ac(dot)cn
Google Scholar
|
GitHub
|
Curriculum Vitae
|
My Mission:
My Mission is to bridge the gap between hardware and software, which means, to help the workloads understand the underlying hardware better and vice versa.
I do research on the characteristics of workloads(ML algorithms, HPC applications, CNN, graph and etc.) and the advanced features of emerging/existing hardware(Xeon Phi, high-end GPU, ARM-neon, and etc), and try my best to squeeze the last ounce of performance.
I'm an assistant professor working with Prof. Yungang Bao in the Center for Advanced Computer Systems (ACS) at Institute of Computing Technology (ICT), Chinese Academy of Sciences (CAS).
I received my Ph.D degree in 2018 at ICT, supervised by Prof. Lixin Zhang and Prof. Jianfeng Zhan, and my master degree at Beijing University of Technology in 2012, supervised by Prof. Jingsha He.
I acquired my bachelor degree at Hebei University of Science and Technology in 2009.
In addition to my advisor, I also work closely with Prof. Xu Liu, Prof. Sally A.McKee, and Dr. Zhen Jia
In the following several years, I will focus on studying computer architecuture and chip design.
I'm fresh to computer architecuture, but always keep moving with great enthusiasm.
I believe that my background, which is also my advantage, on workloads characterization and performance optimizatin will provide me novel perspectives in computer architecture design.
My research interests include: benchmarking, workload characterization, performance optimization, operating system, and computer architecture design.
Projects:
HPConv: high performance winograd-based convolution (2017 ~ Now)
|
This project aims at a high performance implementation of winograd-based convolution, considering sparse, cross-layer data fusion, and strassen based matrix multiplication(MM).
HPConv is preliminary designed for inference-convolution and will be extended to traing-convolution in the future.
|
|
|
SparseLib: high performance library for sparse problems (2017 ~ Now)
|
Numerous applications rely on sparse linear algebra methods or can be cast as sparse problems.
SparseLib focuses on exploiting architectural advances on emerging hardware (wider SIMD lane on Xeon Phi; more processing unit on GPU;...) for various sparse related basic operations, like SpMV, SpMM, sparseFFT, and etc.
|
|
|
PhiBench: Understanding the data analytics workloads on x86 based many-core processors (2014 ~ 2016)
|
The first release of PhiBench consists of eight data analytics workloads, which are delicately optimized on Intel Xeon Phi, an x86 based many-core processor.
We hope that PhiBench is useful for researchers that are interested in understanding data analytics workloads on Intel Xeon Phi.
|
|
|
mobile-Tracking: optimizing body-tracking algorithms on mobile platform (2014 ~ 2015)
|
In this project, we optimize a HOG+FFT based tracking algorithm on NVIDIA TK1. The raw code is written in C/Matlab. We need to investigate the hotspot and accelerate it through parallelization and vectorization.
|
|
|
xMem: Enlarging the memory on co-processors with host memory (2013 ~ 2015)
|
Memory capacity on many co-processors is limited, and unlike host memory, it's hard to increase. In this project, rarely used data on co-processors will be swapped to host memory. Different from classical swap mechanism, swap partition in this project is writable, and can be used for communication between host and co-processors.
|
|
|
pQEMU: Parallel version of QEMU (2012 ~ 2013)
|
QEMU is serial, even when it emulates multiple processors and runs on a multi-core processor. pQEMU aims at accelerating QEMU through multi-threading.
|
|
|
in Preparation:
 |
|
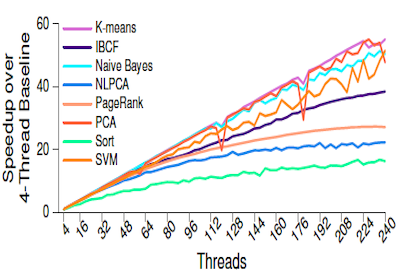
Biwei Xie, Zhen Jia, Wanling Gao, Jianfeng Zhan, and Yungang Bao
The Impact of Data Pattern on SpMV performance
|
|
|
 |
|
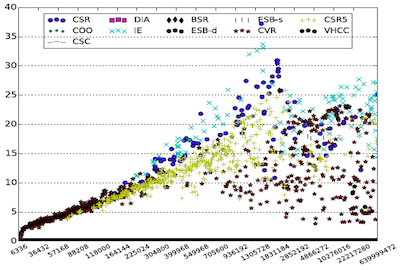
Xinhui Tian, Biwei Xie, and Jianfeng Zhan
Cymbalo: An Efficient Graph ProcessingFramework for Machine Learning
|
|
|
Publications:
2018
 |
|
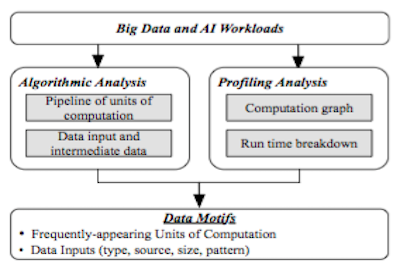
Wanling Gao, Jianfeng Zhan, Lei Wang, Chunjie Luo, Daoyi Zheng, Fei Tang, Biwei Xie, Chen Zheng, Xu Wen, Xiwen He, Hainan Ye, and Rui Ren
Data Motifs: A Lens Towards Fully Understanding Big Data and AI Workloads
In Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques(PACT2018)
|
|
|
 |
|
 |
|
2016
2015
 |
|
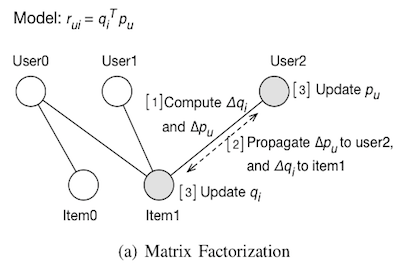
Biwei Xie, Xu Liu, Jianfeng Zhan, Zhen Jia, Yuqing Zhu, Lei Wang, and Lixin Zhang
Characterizing Data Analytics Workloads on Intel Xeon Phi
In Proceedings of the 2015 IEEE International Symposium on Workload Characterization, short paper (IISWC2015)
|
|
|
Patents:
- EP3104275A4, Data processing method, device and system; Lixin Zhang and Biwei Xie; Huawei Technologies Co., Ltd.
Professional Services:
- Sponsorship Chair of Benchmarking, Measuring, and Optimizing (Bench), 2018
- External Reviewer of Parallel Architectures and Compilation Techniques (PACT), 2018
- Reviewer of Transactions on Parallel and Distributed Systems (TPDS), 2018